
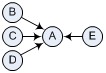
Let’s say we’re representing some information visually with a standard directed graph. We have four nodes (B, C, D, and E) all pointing to another one (A). We have several choices to display the graph. Here are two:


Are they equivalent?
In terms of explicit information being represented, they are. Both diagrams map to the same graph. Spatial placement of nodes is not relevant information in standard graphs (and in fact it is often performed by a visualization algorithm). However, a human will interpret them differently. Even at a glance, the first diagram represents centrality, the second one, hierarchy. More attention leads to more ambiguous and tacit meanings. In the diagram to the left, is node B conceptually “closer” to C than to E? Is it opposed to E? In the diagram to the right, is there a temporal reason for having first B, then C, D, and at last E?
We can play with the spatial structure of graphs a bit more. Each of the following tells a different story:


We humans use many hints and tricks, not always consciously, to communicate among ourselves. When communicating face to face, most of the content of the message is passed not through words, but through tone, volume, body language, and subtle moves, sounds and pauses. Face to face communication is very rich. When communicating with diagrams we also use plenty of extra “channels”. Spatial placement is one, but colours and weights, among others, help us to convey information that is impossible to capture formally:



So we see diagrams convey information implicitly, and a bit ambiguously. People in software projects use them this way all the time. What about other ways to represent information in software development projects? What about code? You’d think software code is a rigid, formal communication tool. It’s not. When communicating through code (yes, we do), we use whitespace, comments, and variable names to convey non-explicit information. Anyone with at least basic code reading skills will be able to detect personal coding styles just as we detect handwriting. We can spot sloppy hack jobs and thoroughly thought out methods; delicate fragments and routine calls.
This richness of communication is only possible thanks to some degree of syntactic flexibility in the languages we use. However, syntactic considerations have a bad reputation in many areas of academic Computer Science (perhaps in every area of Computer Science, except Human-Computer Interaction). Syntactic improvements to programming and modeling languages are second-class to the real stuff, the semantic formalisms and “expressive power”. The clearest indication that this is so is the term we use to refer to syntactic improvements: syntactic sugar.
It’s supposed to be a slightly derogatory term, a disincentive for discussing the topic. The sugar metaphor carries meanings such as the following:
• Sugar is tasty, but unnecessary. We can live without sugar. It adds calories but no nutrients.
• Kids love sugar, but us grownups have a developed palate and only enjoy it in moderate quantities.
• An excess of sugar leads to nasty health problems. Or as Alan Perlis said, “Syntactic sugar causes cancer of the semicolon”
• If a dish is not sweet enough, we can fix it easily: just add some more sugar! Everyone knows how to do it, and there’s no skill involved.
I think the term subsists because many computer scientists and programmers have an antiquated, simplistic model of coding. They believe the only communication act involved in programming is that of the developer formally describing to a computer what instructions to follow:

If this was the case, I would accept that the formal semantics of a language are the only thing that really matters. But in all but trivial cases, programming is not talking to a computer. There are many, many other communication uses of the same code in a development project –most of them among humans:

All of these interactions are vital in software projects. Software development, then, is not just talking to a machine -it’s talking to lots of other people through code and models. And since people will grasp meaning both from semantic and from syntactic cues in code and in models, both need our attention.
(Yes, I’m saying there’s semantics in syntax. Or rather, that our syntax is guided by informal semantics. Or, more eloquently and famously, that the medium is also the message.)
Computer Science loves formalism, but most of real software development consists of informal and implicit exchanges of information among people. Software engineering research must accommodate these informal exchanges. Syntax is not sugar –it is an elementary ingredient to make sense of our projects and activities. It should be studied as such.

Jorge, great post. I think your distinction on how software is ‘really’ developed is fascinating. Perhaps the problem is that the informal semantics of a programming language — e.g., whitespace in Python, semicolons in C, etc. are poorly understood. Determining the effects of these ‘sugar sprinkles’ on programmer effectiveness is difficult to quantify, but I wager there is an effect there.